Shopping Cart
Ohh! Your Basket is empty.
Go to Articles
0 KD
Social recommendation often incorporates trusted social links with user-item interactions to enhance rating prediction. Although methods that aggregate explicit social links have shown promising prospects, they are often constrained by the absence of explicit social data and the assumption of homogeneity, thus overlooking variations in social influence and consistency. These limitations hinder semantic expression and recommendation performance. Therefore, we propose a novel framework for social recommendation. First, we design a bipartite network embedding scheme, which learns vertex representations in the embedding space by modeling 1st-order explicit relations and higher-order implicit relations between vertices. Then, the similarity of the embedding vectors is used to extract top-k semantically consistent friends for each user. Next, we design an algorithm to assign a specific influence value to each user. Finally, we combine the top-k friends of the user and their influence values into an ensemble and add it as a regularization term to the rating prediction process of the user to correct the bias. Experiments on three real benchmark datasets show significant improvements in EISF over state-of-the-art methods.
In recent years, with the rise of online social platforms and explosive growth in internet users, social recommendations based on users’ explicit social relationships have gained widespread attention [1]. The emergence of social recommendations provides a viable solution for addressing the data sparsity issue in recommendation systems, as data sparsity has always constrained recommendation systems, preventing them from fully leveraging their inherent capabilities. In general, social recommendations are built on the influence diffusion model, the basic idea is that users’ preferences tend to be influenced by the friends and key opinion leaders they follow [2]. In other words, the social recommendation is based on the theory of social network homogeneity. It assumes that users and their friends have similar interests and preferences, and user preferences can be modeled by considering the rating behavior of both users and their friends.
Driven by the above theory, researchers have explored many social recommendation models, such as SocialMF [3], and SoRec [4]. In recent times, the successful adoption of graph neural networks in embedding representation learning has accelerated the integration of graph neural networks with social recommendations, leading to the development of various graph neural networks (GNN)-based social recommendation techniques [5,6,7,8].
While social recommendations have evolved from traditional methods to deep learning approaches, applications in complex real-world scenarios and industry surveys [9] indicate that relying solely on explicit social relationships does not always improve recommendation performance. Through investigative analysis, we have summarized several factors that limit further improvement in social recommendation performance.
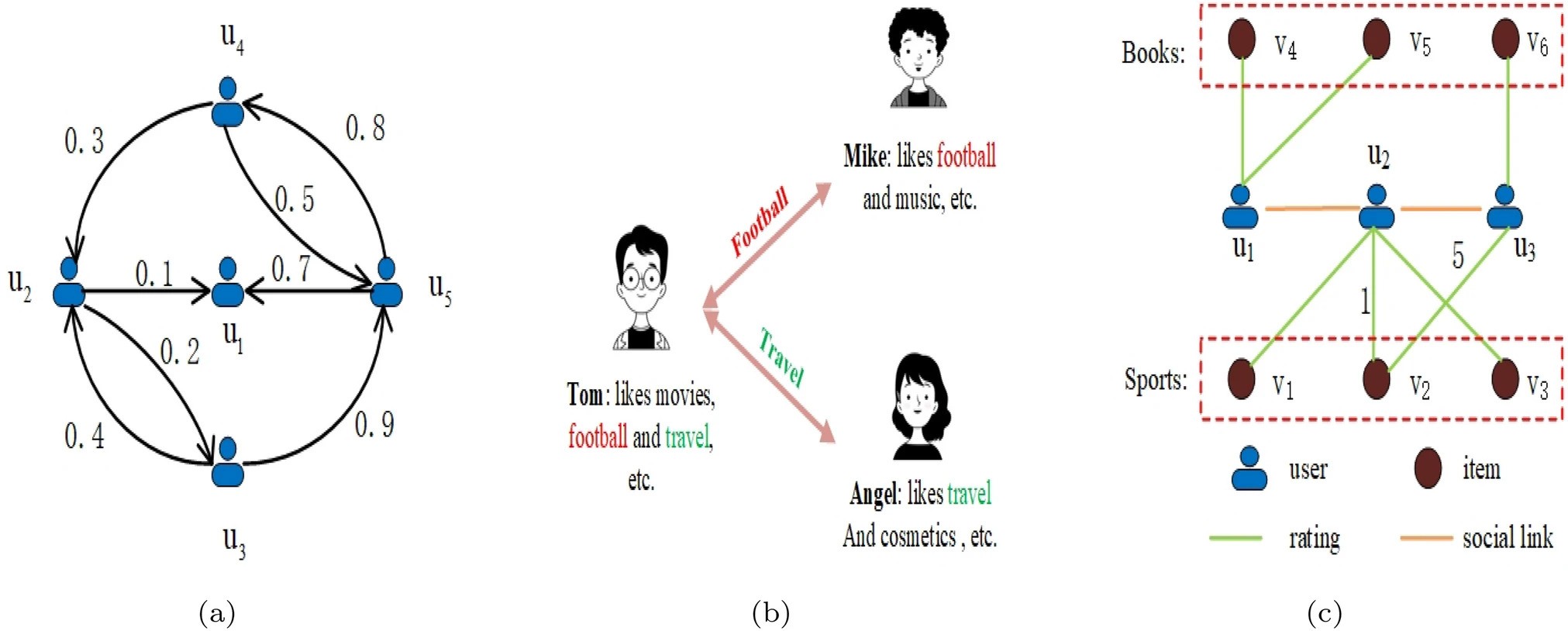
A simple example of a social trust network where sparsity is a great concern but not fully considered in real recommendation. b An example of sharing partial preferences among friends where Tom is a friend of Mike and Angel, but the common preference aspects are distinct (football between Tom and Mike while traveling between Tom and Angel). c An example of a social inconsistency problem, where u1 and u2 are context-level inconsistent neighbors, u2 and u3 exist in relation-level inconsistency
Limitation 1: Insufficient Social Information In reality, due to the purpose of privacy protection, explicit “trust" social information [10] of users is difficult to obtain or even unavailable [11], such as eBay and Netflix. Even if the information is accessible, the social link data is sparse (e.g., the social link density in the Ciao dataset is 0.28%). Figure 1a illustrates a simple trust social network. Obtaining such a social network with trust relationships in realistic recommendation tasks is challenging.
Limitation 2: Lack of Exploration of Implicit Social Relationships and Influence Current methods rarely involve in-depth mining and analyzing users’ implicit relationships. However, in real life, these implicit relationships may exert a greater influence on user preferences in invisible ways [2, 12], such as the celebrity effect. We argue that users with great social influence do not necessarily have an explicit social connection with their followers, as a consequence, how to assign a specific social influence value to a user and use it as a metric to find reliable and most influential friends (not necessarily explicit friends) for a target user is still a challenge.
Limitation 3: Assuming Friends with the Same Preferences Most research assumes that social networks are homogeneous, with users and their explicitly linked friends sharing the same preferences. However, users only share partial preferences with their friends [11, 13]. As is shown in Fig. 1b, Tom is a friend of Mike and Angel, but he only shares similar preferences with Mike in soccer, and similar preferences with Angel in traveling. Therefore, directly aggregating Mike and Angel’s preferences to characterize Tom’s features without distinguishing between them risks misleading recommendation results [11].
Limitation 4: Fail to Consider the Issue of Social Inconsistency The existing methods assume that users maintain a consistent rating prediction process with their social friends. However, we contend that this approach, which relies on incorporating interactive data from socially inconsistent friends as collaborative information for rating prediction, is inadequate to capture users’ interests accurately and undermines system recommendations’ effectiveness. Figure 1c illustrates a social inconsistency problem. u1</math>">�1 and u3</math>">�3 are social neighbors of u2</math>">�2, u1</math>">�1 rated items all belong to books, while u2</math>">�2’s are all sports. u1</math>">�1 and u2</math>">�2 have rather discrepant item contexts. As noted in [14], u1</math>">�1 and u2</math>">�2 would be context-level inconsistent neighbors. We also observe that although u2</math>">�2 and u3</math>">�3 are connected with v2</math>">�2, they have different preference levels for v2</math>">�2. u2</math>">�2 rated v2</math>">�2 with a lower score of 1, demonstrating a dislike of it, while u3</math>">�3 shows great enthusiasm for it with a score of 5. The contrast reveals the problem of relation-level inconsistency.
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.